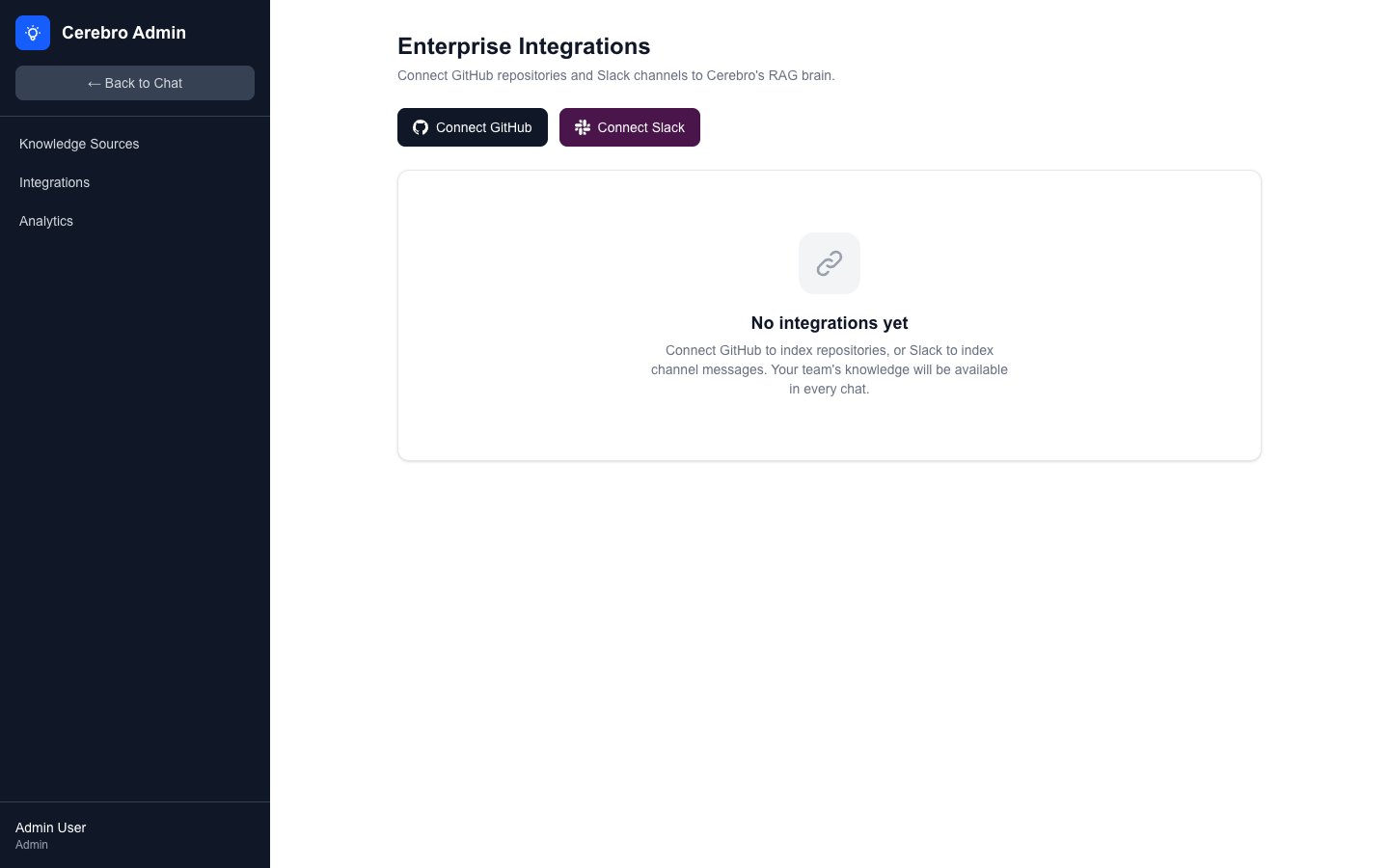
Cerebro is an enterprise knowledge platform that uses retrieval-augmented generation (RAG) to make organizational knowledge instantly accessible — answering questions grounded in company documentation, code repositories, and internal systems rather than generic AI outputs.
The Idea
Teams waste significant time searching for information scattered across wikis, documentation sites, code repositories, Slack threads, and shared drives. Questions get asked repeatedly, answers live in silos, and onboarding new team members means pointing them at a wall of unstructured links. Cerebro was conceived as a single entry point for institutional knowledge — ask a question, get an answer sourced from your own systems, with citations you can verify.
The Execution
Currently in active implementation. The system architecture includes:
- Document ingestion pipeline — connectors for internal wikis, markdown documentation, and code repositories to build a unified knowledge index
- RAG-powered question answering — queries are matched against the indexed knowledge base, with retrieved context used to generate grounded, cited responses
- Source attribution — every answer includes links to the source documents or code sections it was drawn from, enabling verification and deeper exploration
- Repository understanding — the system already answers questions about company codebases, including architectural decisions, function locations, and dependency relationships
- Company knowledge queries — operational questions about processes, policies, and team structures are answerable from ingested documentation
The platform is designed for integration into existing engineering workflows — IDE extensions, Slack bots, and internal tooling — rather than as a standalone search interface.
The Impact
Cerebro is in implementation phase and has not yet been deployed to production. Early internal usage shows the system successfully answering company and repository-specific questions with accurate source attribution. Outcome metrics will be measured after production deployment — initial focus areas are time-to-answer for internal queries and reduction in repeated questions across team channels.
This project represents the enterprise AI integration pattern: taking a well-understood capability (RAG) and applying it to a specific organizational problem (knowledge accessibility) with the architecture, source verification, and workflow integration that enterprise environments require.